
この記事でわかること。
- Rで複雑、大量のクロス集計を効率的に行う具体的なコードの書き方がわかります。
- 実際にサンプルデータを使いながら説明するので、実践的な集計方法が身につきます。
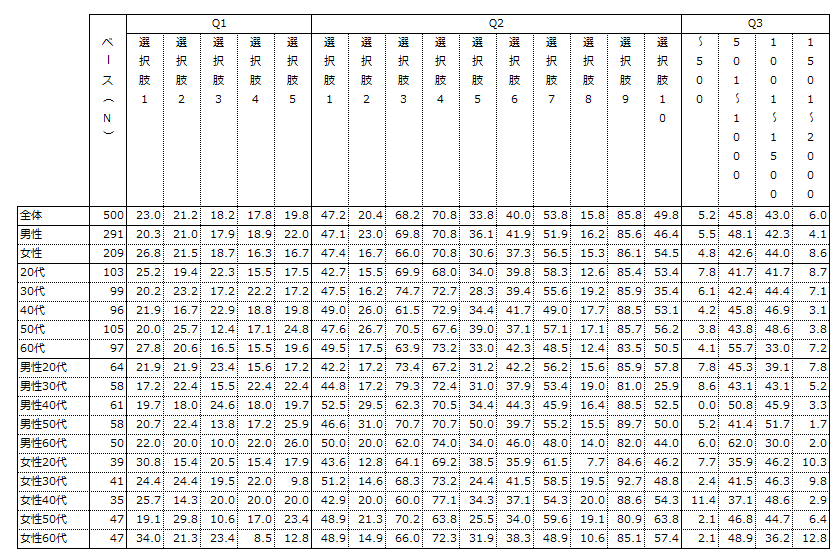
サンプルデータを元にRを使って下のようなクロス集計表を作るためのコードを理解することが目的です。
集計の考え方は以前に紹介したこちらの記事を参照してください。
この記事で紹介するクロス集計の手順です。
メモ
- 集計表に必要なデータ加工を行う(年齢から20代、30代・・などのデータを作成する)
- 集計に必要な項目のデータを01の形にする(該当する列に1が入力され、非該当の列に0が入力されている形のデータを作成します)
- 行列の計算(乗算)により実数表(N表)を作成する
- 実数表を全体で割り算を行い、%表を作成する
まず集計に利用するサンプルデータを作成します。
データの概要としては、性別、年齢の属性データと、アンケートで回答するQ1~Q3です。
- Q1:シングルアンサーのデータ(5つの選択肢から1つだけ回答するイメージ)
- Q2:マルチアンサーのデータ(10個の選択肢からあてはまるものをいくつでも回答するイメージ。あてはまる選択肢は「1」、あてはまらない選択肢は「0」が入力されている。)
- Q3:数量データ(金額のデータをイメージ)
サンプルデータを作成するコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
library(tidyverse) set.seed(1)#再現性を維持するためにseedを設定 #-----サンプルデータを作成 #性別のデータ sei <- rbinom(500,1,0.46) sei[sei==0] <-"男性" sei[sei==1] <-"女性" #年齢のデータ age <- as.integer(runif(500,min = 20,max = 69)) #アンケートをイメージしたデータを作成(全部で3問) #シングルアンサーの設問 1~5の乱数データを作成 Q1 <- as.integer(runif(500,min = 1,max = 6)) #マルチアンサーの設問 0or1のデータを10カラム分作成 Q2 <- cbind(Q2_01 = rbinom(500,1,0.46), Q2_02 = rbinom(500,1,0.21), Q2_03 = rbinom(500,1,0.66), Q2_04 = rbinom(500,1,0.74), Q2_05 = rbinom(500,1,0.33), Q2_06 = rbinom(500,1,0.42), Q2_07 = rbinom(500,1,0.56), Q2_08 = rbinom(500,1,0.16), Q2_09 = rbinom(500,1,0.86), Q2_10 = rbinom(500,1,0.46)) #数量データの設問 平均1000 標準偏差300の乱数を作成 Q3 <- as.integer(rnorm(500,1000,300)) #すべてデータをまとめる df <- data.frame(sei,age,Q1,Q2,Q3) df %>% head() |
では、早速先ほど作ったサンプルデータを利用してクロス集計を行いましょう。
Contents
集計表に必要なデータ加工を行う(年齢から20代、30代・・などのデータを作成する)
最終的な表にする際に選択肢の名称が思った通りの順番にならないことがあるので、アイテムごとに「01_」といったように連番を追加する加工を行います。(五十音順だと性別は、女性→男性の順になってしまう)
下のコードでは、データフレームdfに「seicate」というカラム名の列を追加し、「seicate」のデータは「01_男性」「02_女性」のいずれかが入るイメージです。
|
1 2 |
df <- df %>% mutate(seicate =case_when(sei == "男性" ~ "01_男性", sei == "女性" ~ "02_女性")) |
続いて、年齢のデータから10歳刻みのデータを作成します。
性別と同様に、「agecate」というカラム名で「01_20代」~「05_60代」がデータとして入力された列を追加します。
|
1 2 3 4 5 |
df <- df %>% mutate(agecate =case_when(age <30 ~"01_20代", between(age ,30,39) ~ "02_30代", between(age ,40,49) ~ "03_40代", between(age ,50,59) ~ "04_50代", between(age ,60,69) ~ "05_60代")) |
10歳刻みのデータと性別のデータを使って性年代のデータを作成します。
こちらも「seiage」というカラム名でデータの中身は「01_男性20代」~「10_女性60代」です。
|
1 2 3 4 5 6 7 8 9 10 |
df <- df %>% mutate(seiage = case_when(sei=="男性" & age <30 ~"01_男性20代", sei=="男性" & between(age ,30,39) ~"02_男性30代", sei=="男性" & between(age ,40,49) ~"03_男性40代", sei=="男性" & between(age ,50,59) ~"04_男性50代", sei=="男性" & between(age ,60,69) ~"05_男性60代", sei=="女性" & age <30 ~"06_女性20代", sei=="女性" & between(age ,30,39) ~"07_女性30代", sei=="女性" & between(age ,40,49) ~"08_女性40代", sei=="女性" & between(age ,50,59) ~"09_女性50代", sei=="女性" & between(age ,60,69) ~"10_女性60代")) |
Q3の数量のデータを500刻みでカテゴリー化します。
「Q3cate」というカラム名で「01_500以下」~「04_1501~2000」といったデータが入ります。
|
1 2 3 4 |
df <- df %>% mutate(Q3cate = case_when(Q3 <= 500 ~ "01_500以下", between(Q3,501,1000) ~ "02_501~500", between(Q3,1001,1500) ~ "03_1001~1500", between(Q3,1501,2000) ~ "04_1501~2000")) |
集計に必要な項目のデータを01の形にする
これまでの作業で作成したデータをそれぞれ01化する作業を行います。
例えば下のように性別の列を男性の01、女性の01といった形に変換をします。
|
性別 |
|
男性 |
|
女性 |
|
男性 |
|
女性 |
↓
|
性別_男性 |
性別_女性 |
|
1 |
0 |
|
0 |
1 |
|
1 |
0 |
|
0 |
1 |
この変換作業はdummiesライブラリーのdummy.data.frame関数を利用します。
|
1 2 |
library(dummies) dummies::dummy.data.frame(変換したいデータフレーム, sep="_",dummy.classes = "ALL") |
「変換したい元の列名+実際のデータ」の組合せて新しい列の名前が作成されますが、sepでは元の列名と実際のデータを結合する際の間に挟む文字列を指定します。
先ほどの性別のデータの例だと、元の列名が「性別」データは「男性」or「女性」です。sep=”_”と指定すると新しいカラム名は「性別_男性」「性別_女性」といった形になります。
実際のコードはこちら。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#Q1のデータを01に変換 Q1 <- df %>% select(Q1) #dfからQ1のデータを選択 #Q1のデータを01化してQ1_01に格納する。 Q1_01 <- dummies::dummy.data.frame(Q1,sep="_",dummy.classes = "ALL") #Q2のデータは元々01のデータですが、Q2_01、Q2_02・・と複数の列を選択する必要があるのでstarts_withを使っています。 #starts_withはQ2から始まる列を選択する Q2 <- df %>% select(starts_with("Q2")) #Q3のデータを01に変換。Q1と同様の手順 Q3cate <- df1 %>% select(Q3cate) Q3cate01 <- dummies::dummy.data.frame(Q3cate,sep="_",dummy.classes = "ALL") #性年代データを01に変換。性別、年代、性年代を一括で処理しています。 sei_age <- df1 %>% select(seicate,agecate,seiage) sei_age01 <- dummies::dummy.data.frame(sei_age,sep="_",dummy.classes = "ALL") |
行列の計算(乗算)により実数表(N表)を作成する
ここまでで、集計に必要なデータの加工の準備は終わりました。続いて行列の計算を行いますが、簡単に意図の説明だけ復習します。
↓のように性別と年代のデータから表頭が年代(10代~30代)、表側が性別(男性~女性)の件数表(N表)を作成する場合は
|
性別_男性 |
性別_女性 |
年代_10代 |
年代_20代 |
年代_30代 |
|
1 |
0 |
1 |
0 |
0 |
|
0 |
1 |
0 |
1 |
0 |
|
1 |
0 |
0 |
0 |
1 |
|
0 |
1 |
0 |
1 |
0 |
|
0 |
1 |
1 |
0 |
0 |
性別のデータ(行列)を転置したものと、年代のデータ(行列)を下記の行列と考えて、
※性別に小さなtがついているのは、転置((i, j) 要素と (j, i) 要素を入れ替えてできる n 行 m 列の行列))していると言う意味です。

性別の転置行列と年代の行列の積を求めると、性別×年代の件数表が作成することができます。
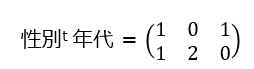
上の行列は下の件数表を同じ意味です。
行列の数字と、下の表の数字を照らし合わせると同じものとわかると思います。(1行目・1列目は1、1行目2列目は0といった感じで全てのセルを確認してみてください。)
このあたりの理屈は、前の記事を確認してもらったほうが理解できると思います。
|
年代_10代 |
年代_20代 |
年代_30代 |
|
|
性別_男性 |
1 |
0 |
1 |
|
性別_女性 |
1 |
2 |
0 |
では、先ほど加工したデータを使って実際に行列の積を求めます。まず、件数表の項目(表の上側)に該当する行列を作成します。
ベース(N)とQ1~Q3が項目となっていますので、ベース(N)とQ1~Q3の01のデータとまとめた行列にを作成します。
|
1 2 3 |
#件数表の項目をまとめる top <- cbind(Q1_01,Q2,Q3cate01) %>% mutate(ベース=1) %>% relocate(ベース) top <- as.matrix(top) #行列の計算はマトリックス形式で行うためデータフレームからマトリックスへ変換。 |
※ベース(N)とは%を計算するうえでの母数(分母)となる部分です。
つまりこの件数表の場合、全員の人数、男性全体の件数、女性全体の件数、・・と言ったものが必要となります。項目の行列にすべてが「1」=該当するのデータを追加します。mutate(ベース= 1)の部分ですべてが「1」の列を追加、relocate(ベース)の部分でベースの列を一番最初に移動しています。
続いて、表の横の部分の行列を作成します。
|
1 |
side <- sei_age01 %>% mutate(全体=1) %>% relocate(全体)) |
行列の計算(乗算)により実数表(N表)を作成する
表の項目と表の横の部分ができたので、表の横の行列を転置して、これらの行列の積を求めます。
|
1 2 |
cross <- t(side) %*% top #t(side)でsideを転置。転置するとマトリックス型になり、「%*%」は行列の積を計算する記号です。 |
実数表を全体で割り算を行い%表を作成する
最後に実数表をベースで割り算と100倍することでパーセント表にします。
|
1 2 3 4 |
cross_per <- cross #念のため件数表を取っておきたいので、別のオブジェクトにコピーします。 cross_per[,2:ncol(cross_per)] <- 100* cross_per[,2:ncol(cross_per)] / cross_per[,1] #件数表のベースを除く部分(2列目以降= cross_per[,2:ncol(cross_per)])を #ベースの列(1列目= cross_per[,1])で割り100倍し、件数表に上書きしています。 |
まとめ
改めて流れをおさらいすると、以下の通りです。
メモ
- クロス集計表の完成イメージを作成する
- クロス集計表の項目(表の上側)と表の横の部分の01データを作成する
- 表の項目はmatrix形式に、表の横の部分は転置する
- 3で作成したデータから行列の積を求める。
- ベース(%の分母にあたる部分)で件数表を割り100倍する
普段の業務では、この流れに加えてチェック工程が入ります。
クロス集計の結果をすべてチェックすることは工数的にも難しいと思います。特に、表頭・表側の項目が増えると・・さらに厳しい。ただ、ノーチェックというわけにはいかないので、私は表頭と表側の件数のみをチェックすることにしています。
表頭、表側の件数が間違っていなければ、クロス集計の結果も間違いないだろう・・との考え方からです。その際、パーセントのデータだと計算誤差があるためチェックがしづらいので、4の行列の積を作成した時点の件数ベースでチェックをしています。
今回は簡単な例で説明しましたが、この方法でクロス集計を行うと表頭・表側の項目が増えても01の行列形式のデータにすればいいだけなのでそれほど作業量が増えません。
また、01化するのもdummy.data.frame関数を使えばよいだけなので、大変ではありますが大量の集計データを作成する場合はこの方法を使って作業することをお勧めします。
それでは。