
この記事でわかること。
- データフレームの複数の列の合計したカラムを追加する方法を解説します。
エクセルなどスプレッドシートで表現すると↓のようなことをするイメージです。エクセルだとsum関数なりで簡単にできますが、R初心者だとこんな簡単なことも難しかったりしますよね。
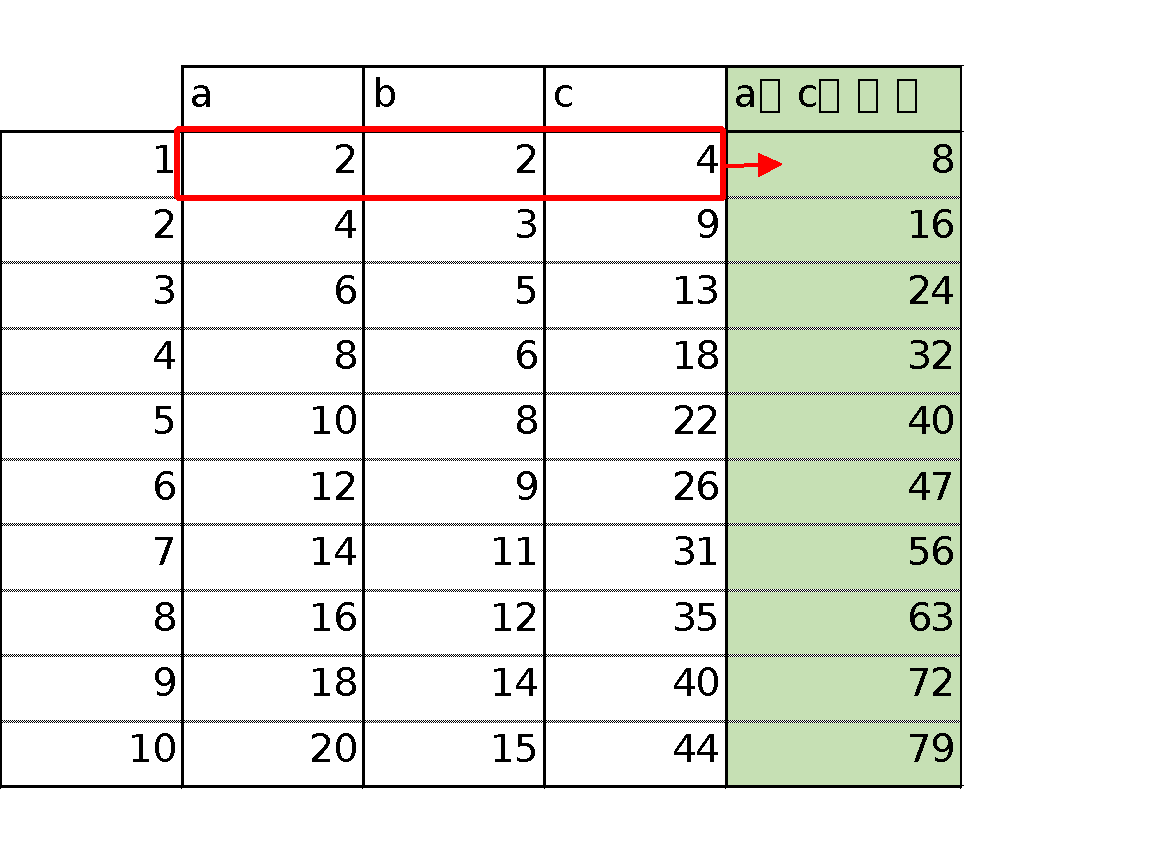
では、始めていきます。
列の合計の記述の仕方
まず、サンプルデータを作ります。このデータを例に話を進めます。
|
1 2 3 4 5 6 7 8 |
df <- data.frame(x1=c(1,2,3),x2=c(2,3,4),x3=c(1,2,4)) df x1 x2 x3 1 1 2 1 2 2 3 2 3 3 4 4 |
Rで行の合計を計算する場合はいくつかの書き方があって、状況によって使い分けてほしいのですが、私が良く使うのは以下の2つの方法です。
列の合計を計算する方法1:rowSums関数を利用する方法
書き方の例
|
1 2 3 |
rowSums(df) 4 7 11 |
解説
rowSums(データフレーム)と書けば、データフレームの列の合計が計算されます。
※データフレームに文字列型など計算できないデータが含まれているとエラーになります。
列の合計を計算する方法2:apply関数を利用 する方法
書き方の例
|
1 2 3 |
apply(df, 1 ,sum) 4 7 11 |
解説
apply(データフレーム,1,sum)と書きます。
・最初の引数でデータフレームを指定します。
・2つ目の引数「1」で計算する方向を指定します。1ならば行方向、2ならば列方向に計算します。今回は行方向の合計を計算するので1と指定しました。
・3つ目の引数で計算の方法を指定します。合計を計算したいのでsumと書きましたが、平均を計算したい場合はmean、
分散を計算したい場合はvarとします。合計以外にも使えるのでこちらの方が応用が利きますね。
列の合計をデータフレームに追加する方法
dplyrパッケージのmutate関数を利用します。
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = rowSums(df)) x1 x2 x3 sum_ex 1 1 2 1 4 2 2 3 2 7 3 3 4 4 11 |
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = apply(df, 1, sum)) x1 x2 x3 sum_ex 1 1 2 1 4 2 2 3 2 7 3 3 4 4 11 |
解説
mutate(追加する列名 = 追加する列の計算内容)と書きます。今回の例ではすべての列を合計しているのでrowSums(df)と書きましたが、特定の列を指定する場合はもう少し複雑な書き方になります。
特定のカラムの合計を計算する方法
ここからはデータフレームのすべての列の合計を追加するのではなく、データフレームの特定の列の合計の列を追加する方法を説明します。
エクセルなどスプレッドシートで表現すると↓のようなことをするイメージです。
先ほどのとの違いは、カラムaとcの合計を計算しているところです。
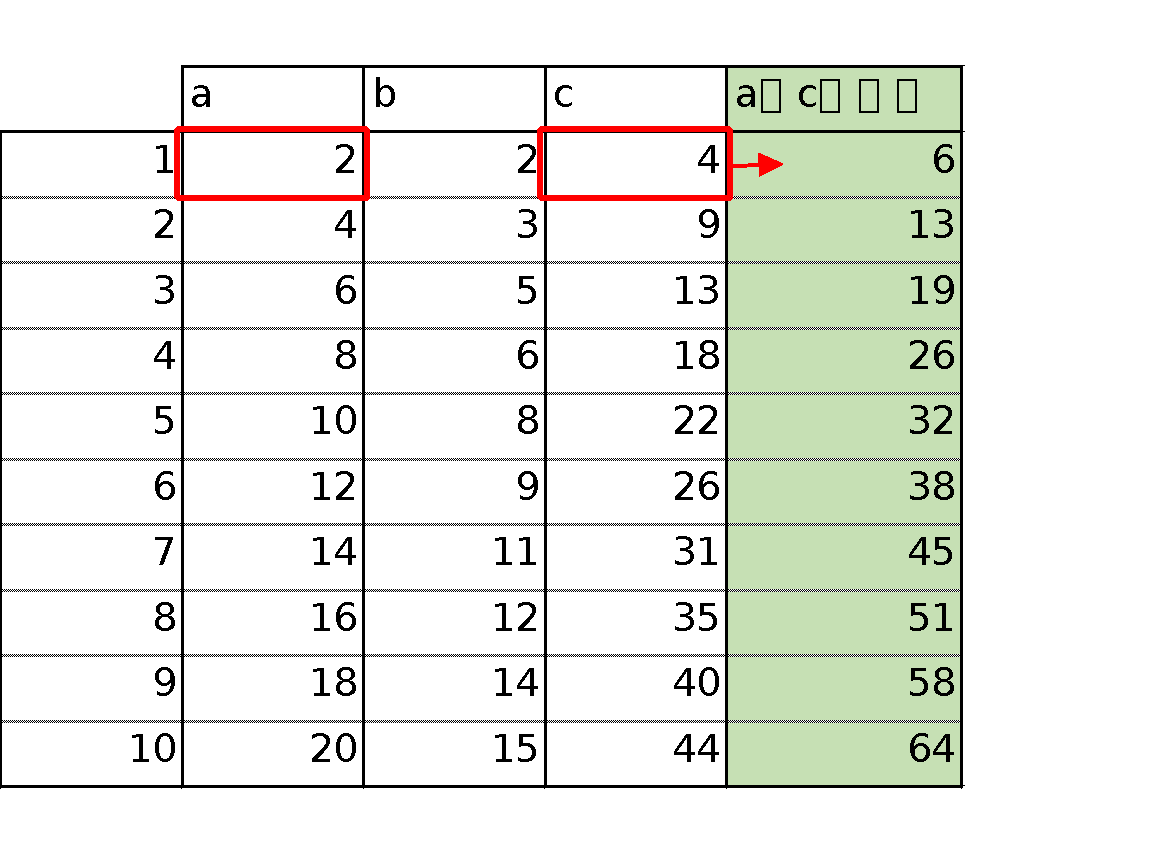
カラム番号を指定して合計の列を追加する方法
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = rowSums(df[,c(1,3)])) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = apply(df[,c(1,3)], 1, sum)) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
解説
データフレームの列番号を指定して合計を計算しています。ベクトルで行番号を指定すれば上の様に1列目と3列目の合計が計算できます。
カラム名を指定して合計の列を追加する方法
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = rowSums(df[,c ("x1","x3")])) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
書き方の例
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = apply(df[,c("x1","x3")], 1, sum)) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
解説
カラム番号と同じでベクトルで列名を指定します。ダブルクォーテーションで囲むところに注意です。
カラム番号やカラム名を指定して合計の列を追加するモダンな方法
書き方の例(列名)
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = select(.,c(x1,x3)) %>% rowSums(na.rm=TRUE)) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
書き方の例(列番号)
|
1 2 3 4 5 6 |
df %>% mutate(sum_ex = select(.,c(1,3)) %>% rowSums(na.rm=TRUE)) x1 x2 x3 sum_ex 1 1 2 1 2 2 2 3 2 4 3 3 4 4 7 |
解説
先ほどとの違いは、select関数で合計する列を指定しているところです。
「select(.,」の部分はパイプで参照しているデータの列を選択することを意味します。
今回の場合だとdfというデータフレームの中からカラムを選択します。と言う意味になります。「select(.,c(x1,x3))」「select(.,c(1,3))」はdfの中からx1、x3のカラムを選択する、1列目、3列目を選択すると言う意味です。
「%>% rowSums(na.rm=TRUE)」の部分で選択したカラムの合計を計算する指示を出しています。※「na.rm=TRUE」は合計を計算する列に欠損値があった場合、欠損値を無視する書き方です。基本的には常にこの記述をしておいてOKだと思います。
applyで同じように記述する場合は、「%>% rowSums(na.rm=TRUE)」の部分を「%>% apply(.,1,sum)」に変えればOKです。
最初の引数が「.」になっているのはselect関数と同じで、「%>%」で引き継がれた変数を最初の引数に指定する意味です。
この書き方をマスターするとdplyrのselect関数を使ったカラム選択をそのまま使えるので、カラムの選択方法に幅が広がります。
次に応用的な方法を説明します。
カラム番号やカラム名を指定して合計の列を追加する応用的な方法
ここからはirisのデータを利用して説明します。
前方一致、後方一致、含み選択でカラム名を取得して合計を計算する方法
書き方の例
|
1 2 3 4 5 6 7 8 9 |
iris %>% mutate(Sepal_sum = select(.,starts_with("Sepal")) %>% rowSums(na.rm=TRUE)) %>% head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species Sepal_sum 1 5.1 3.5 1.4 0.2 setosa 8.6 2 4.9 3.0 1.4 0.2 setosa 7.9 3 4.7 3.2 1.3 0.2 setosa 7.9 4 4.6 3.1 1.5 0.2 setosa 7.7 5 5.0 3.6 1.4 0.2 setosa 8.6 6 5.4 3.9 1.7 0.4 setosa 9.3 |
解説
select(.,starts_with("Sepal"))の部分で「Sepal」から始まる列を指定しています。後方一致はstarts_withをends_withに変更。含み選択であればcontainsに変更すればOKです。
データ型からカラムを取得して合計を計算する方法
書き方の例
|
1 2 3 4 5 6 7 8 9 |
iris %>% mutate(sum_all = select(.,where(is.numeric)) %>% rowSums(na.rm = TRUE)) %>% head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species sum_all 1 5.1 3.5 1.4 0.2 setosa 10.2 2 4.9 3.0 1.4 0.2 setosa 9.5 3 4.7 3.2 1.3 0.2 setosa 9.4 4 4.6 3.1 1.5 0.2 setosa 9.4 5 5.0 3.6 1.4 0.2 setosa 10.2 6 5.4 3.9 1.7 0.4 setosa 11.4 |
解説
Where(is.numeric) の部分でnumeric型のカラムのみを選択しています。Species以外を合計する書き方としては、Species がfactor型なので次のような方法でも可能です。
|
1 2 3 4 5 6 7 8 9 |
iris %>% mutate(sum_all = select(.,!where(is.factor)) %>% rowSums(na.rm = TRUE)) %>% head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species sum_all 1 5.1 3.5 1.4 0.2 setosa 10.2 2 4.9 3.0 1.4 0.2 setosa 9.5 3 4.7 3.2 1.3 0.2 setosa 9.4 4 4.6 3.1 1.5 0.2 setosa 9.4 5 5.0 3.6 1.4 0.2 setosa 10.2 6 5.4 3.9 1.7 0.4 setosa 11.4 |
カラムの名前リストを使ってカラムを選択する方法
|
1 2 3 4 5 6 7 8 9 10 |
namelist <- c("Sepal.Length","Petal.Width") iris %>% mutate(sum_ex = select(.,all_of(namelist)) %>% rowSums(na.rm = TRUE)) %>% head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species sum_ex 1 5.1 3.5 1.4 0.2 setosa 5.3 2 4.9 3.0 1.4 0.2 setosa 5.1 3 4.7 3.2 1.3 0.2 setosa 4.9 4 4.6 3.1 1.5 0.2 setosa 4.8 5 5.0 3.6 1.4 0.2 setosa 5.2 6 5.4 3.9 1.7 0.4 setosa 5.8 |
解説
カラム名のベクトルの形で変数namelistを作成します。
select(.,all_of(namelist))で合計するカラムを指定します。all_ofの部分でカラムを選択しますが、all_ofではnamelistのすべてのカラムをirisから選択しようとするので、namlistにあってirisにないカラムが存在する場合エラーとなってしまいます。
namelistの中でないものを無視して選択する場合はall_ofの代わりにany_ofを利用します。
まとめ
色々な方法を紹介しましたが、紹介した方法を使いこなせれば列方向の操作はある程度のことができるようになると思います。
利用シーンとしては、
メモ
- 購買データなどで購入商品の個数のデータのカラムが複数ある場合など、紹介した方法で購入した商品数の合計を計算する。
- 定期的に行われるイベントの来場の0 or 1のデータを合計して、年間の来場回数を計算する
などいろいろなケースで利用することが多いです。
私も色々なデータの分析をする際この方法を結構な頻度で使うので、基本的なことであれば特に調べることなくさらっと書くことができるようになりました。
システム開発と違ってデータの分析の場合、試行錯誤が何度も発生するのでコードの記述を調べる回数をできるだけ減らすと効率が劇的に上がると個人的には考えています。
分かるから使えるにするために、色々なデータに触れて繰り返し使って体に覚え込ませることが重要だと思います。
それでは。